Azkabanの紹介
Azkabanはワークフローを実行するジョブスケジューラーです。Hadoopジョブを実行するためにLinkedIn社で開発されました。Azkabanは順序立ててジョブの依存関係を解決し、ワークフローのメンテナンスと保守・運用を実現します。
Hadoop向けに開発されたソフトウェアですが、Hadoopジョブでなければ利用できないものではありません。
オープンソースで提供されており、Apache2.0ライセンスです。開発で使われているプログラミング言語はJavaです。リリースされているバージョンは3.x系で、現在4.x系の開発が行われています。
Azkaban はLinkedIn社で2009年に使われ始めました。3.x系は2014年から使われています。LinkedIn社では毎日25,000のジョブフローがAzkabanクラスター上で動作しています。
Azkabanの主な機能と特徴
主な機能を列挙します。
- ウェブUI
- ワークフローのスケジューリング
- ワークスペース管理
- ジョブのリトライ
- 認証機能(ジョブの権限管理)
- ワークフローとジョブのロギングと監査機能
- 通知機能
Azkabanには有料版または有料ホスティングサービスがありません。利用する場合は自社内でサーバーの保守も行う事になります。
LinkedIn社ではHadoop、ETL、Apache Spark、機械学習やリアルタイムデータのフローにも利用しているそうです。
インストール手順
Ubuntu16.04 LTSにAzkaban をインストールする手順を説明します。
Java8以上と指定されていますのでopenjdk-8をインストールします。
$ sudo apt-get update $ sudo apt-get install openjdk-8-jdk
Azkabanのプロジェクトをgithubからcloneしフォルダを移動します。
$ git clone https://github.com/azkaban/azkaban.git $ cd azkaban;
gradleでビルドを行います。
$ ./gradlew build installDist
ビルド中に<============-> 97% EXECUTINGと表示された所から進まなくなってしまいました。仕方なしに-x testを付けテストを除外して再ビルドします。
$ ./gradlew build -x test installDist
BUILD SUCCESSFULと表示されればビルドに成功です。
次にsolo-serverを起動しますので、solo-server以下に移動します。
$ cd azkaban-solo-server/build/install/azkaban-solo-server
solo-serverを起動します。
$ bin/azkaban-solo-start.sh
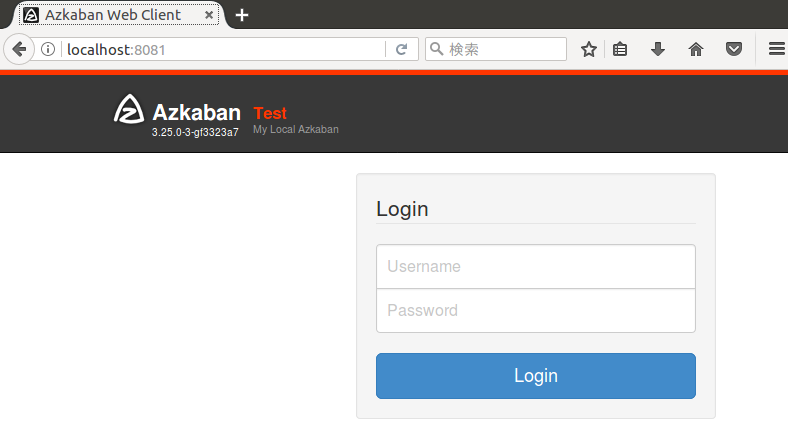
8081ポートで起動しますので、http://localhost:8081/にアクセスしてログインフォームが表示されれば起動に成功です。
デフォルトのログイン情報は、ユーザー名がazkaban、パスワードも同じくazkabanです。
ログインに成功するとプロジェクトの一覧ページに遷移します、最初は何も登録されていません。
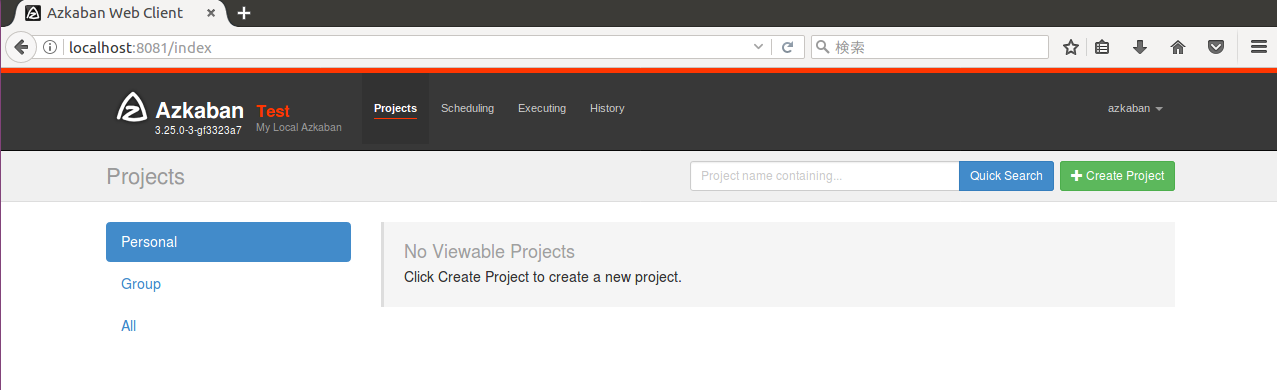
データベースの指定を行っていませんが、データベースを指定しない場合は標準でJavaに組み込まれているH2データベースが利用されます。
Azkabanの使い方を説明
無事にインストールできたので使い方を説明します。
プロジェクトの作成
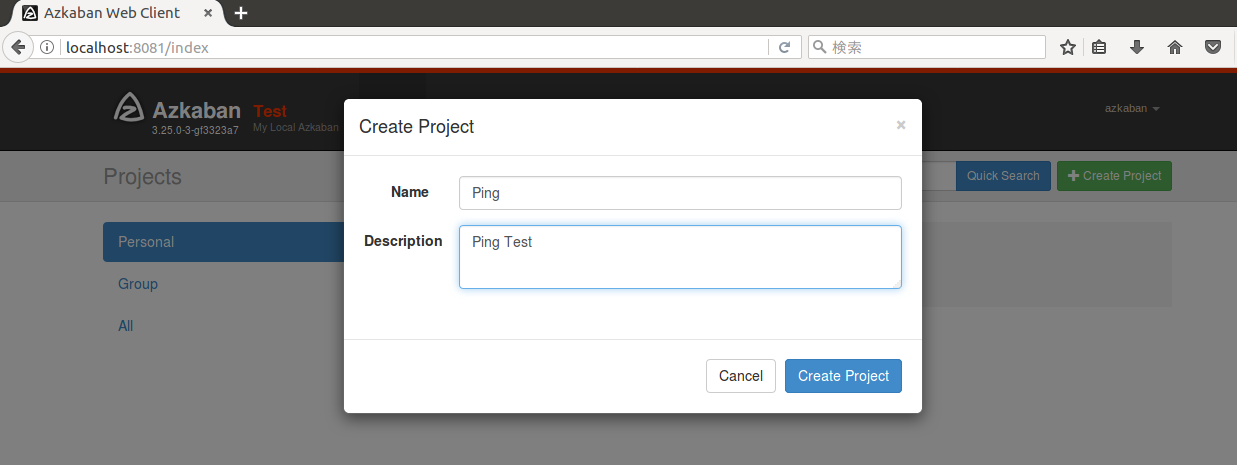
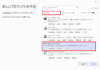
ログイン後、右上にある「Create Project」ボタンを押して新しくプロジェクトを追加します。ここではPingを実行するワークフローを試すためNameにPingと分かる様に入力してダイアログ右下の「Create Project」ボタンを押します。
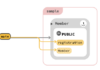
新規プロジェクトが作られました。
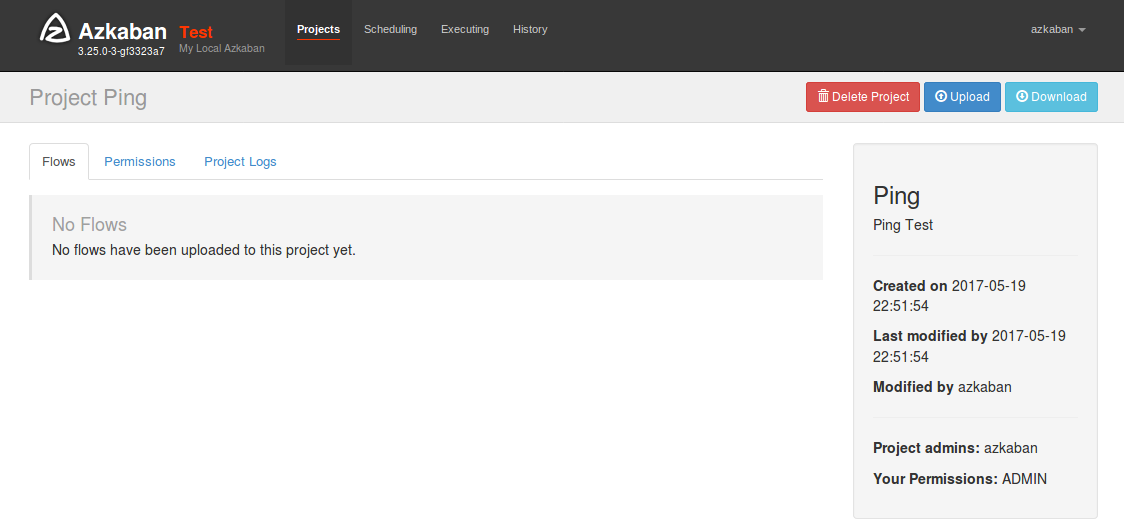
フローの実行
次にpingを5回実行するジョブを作ります。拡張子は.jobにします。
$ vi ~/ping.job type=command command=ping -c 5 yahoo.co.jp
jobをzipファイルに固めます。
$ zip archive ~/ping.job -O ~/ping.zip
右上のあるUploadボタンを押し、ping.zipを選択してダイアログ内右下の「Upload」ボタンを押すとフローが登録されます。
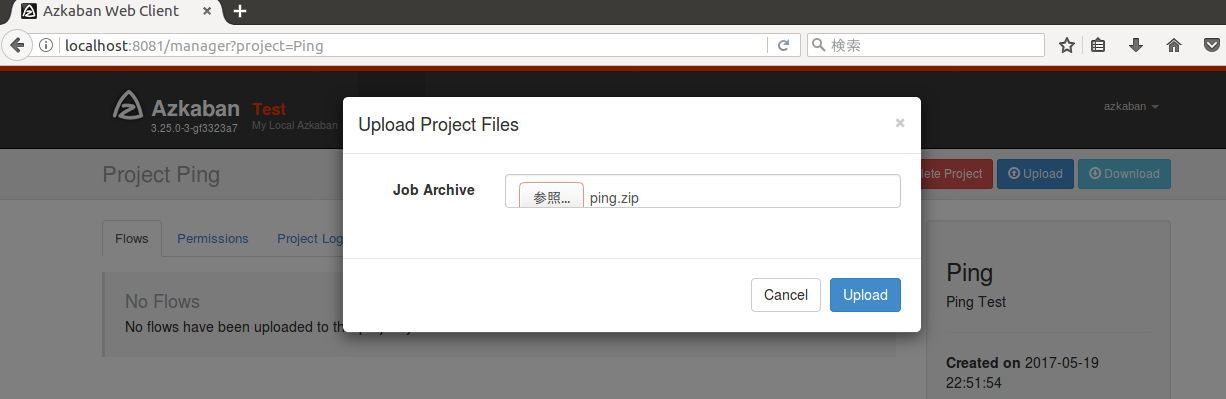
アップロードに成功しました。「Execute flow」ボタンを押しフローを実行します。
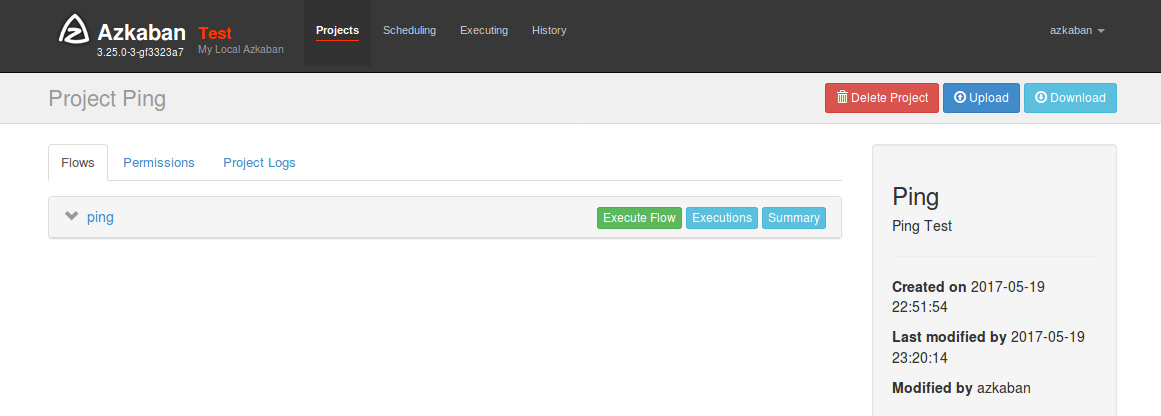
フロービューが開きました。ここでは通知ルールやフローが利用するパラメーターを指定できます。ダイアログの右下にある「Execute」ボタンを押します。
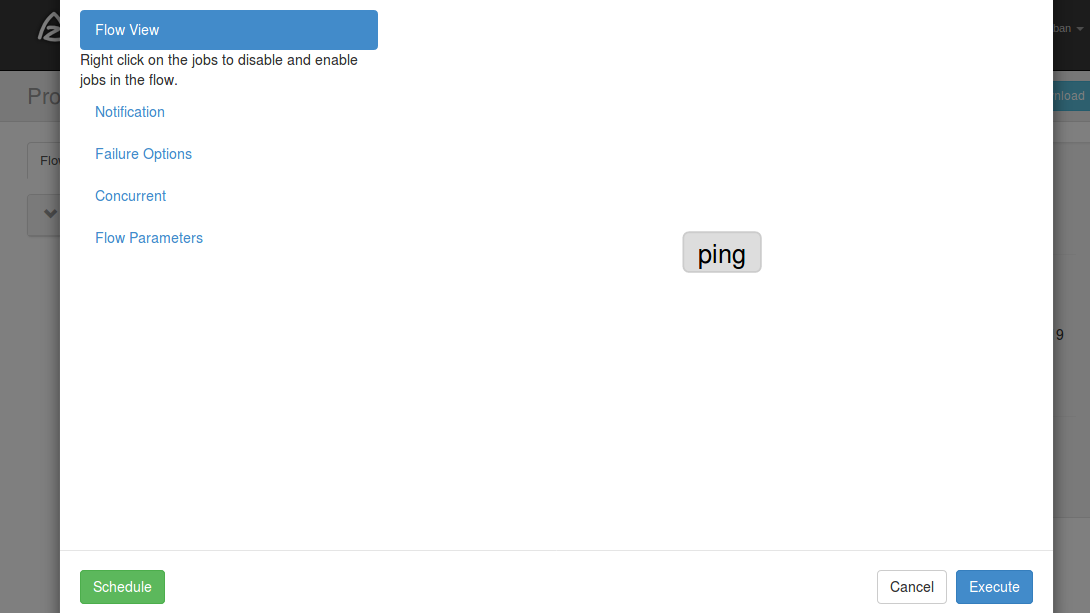
フローが実行されました。
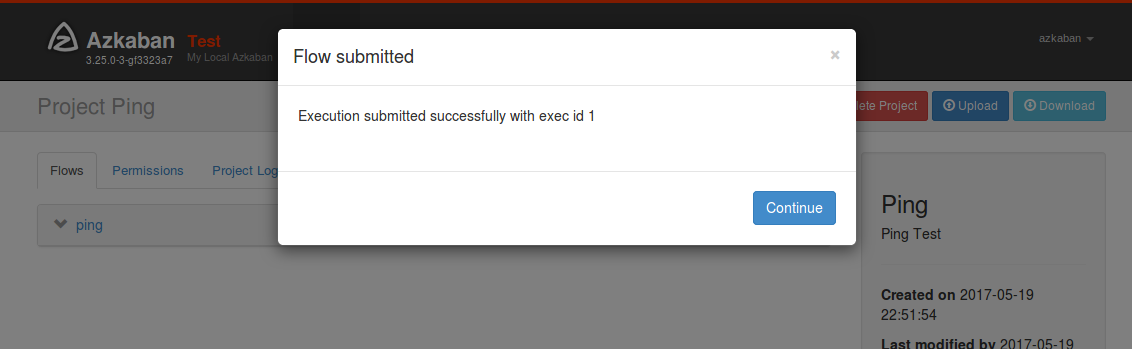
少し待つとジョブが完了するはずですが、runningから状態が変化しません。調べるとエラーが発生していました。メモリが不足しておりスリープしてはリトライを繰り返しています。
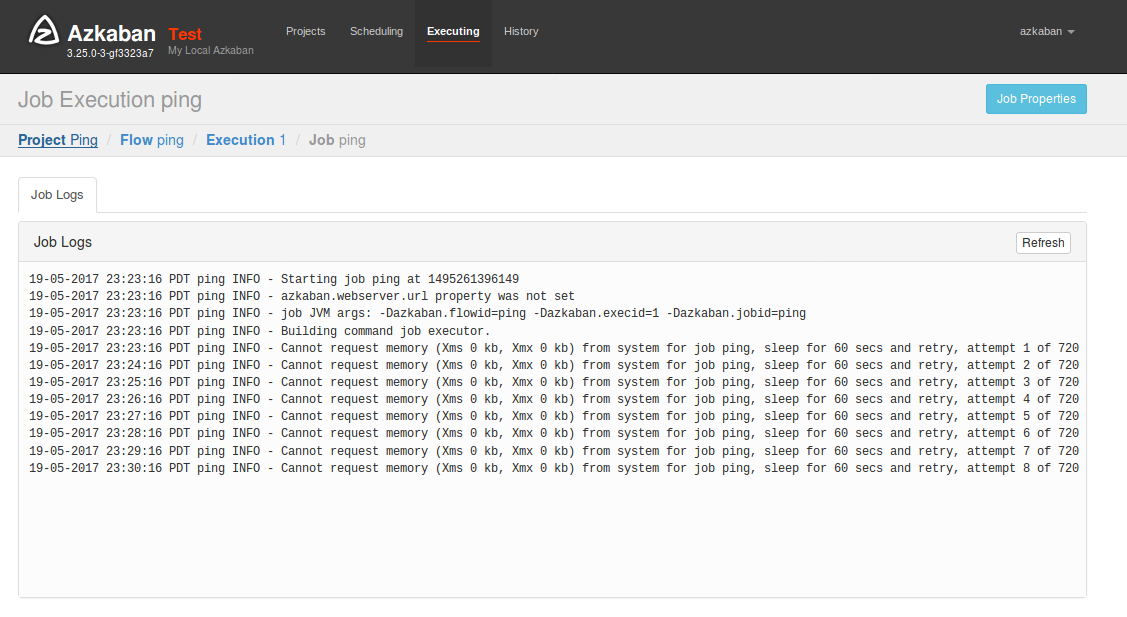
メモリを2G割り当てていましたが足りないようです。メモリ量の推奨が3G以上のようなので本記事中では仮想環境のメモリ割り当てを2Gから4Gに増やしてから再度実行しました。
再起動してから再度azkaban-solo-serverを実行すると以下エラーが発生するようになってしまいました。
azkaban.executor.ExecutorManagerException: Flow does not exist
もしazkaban-solo-serverを起動してエラーが表示されるようであれば、bin/azkaban-solo-shutdown.shを利用し停止した後にh2データベースのファイルを削除して再度起動します。
$ bin/azkaban-solo-shutdown.sh $ rm h2.mv.db h2.trace.db $ bin/azkaban-solo-start.sh
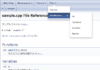
ページ上部のナビゲーションのExecutingからRecently Finishedタブを押すと状態が成功になっている事を確認できます。Execution Idの数字を押すと詳細を確認できます。
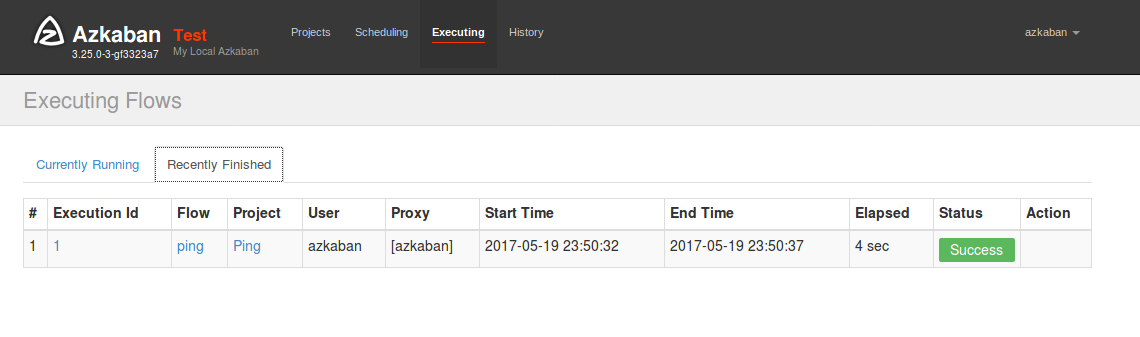
詳細ページのJob Listタグを開き、テーブル右端にあるDetailsリンクを押します。
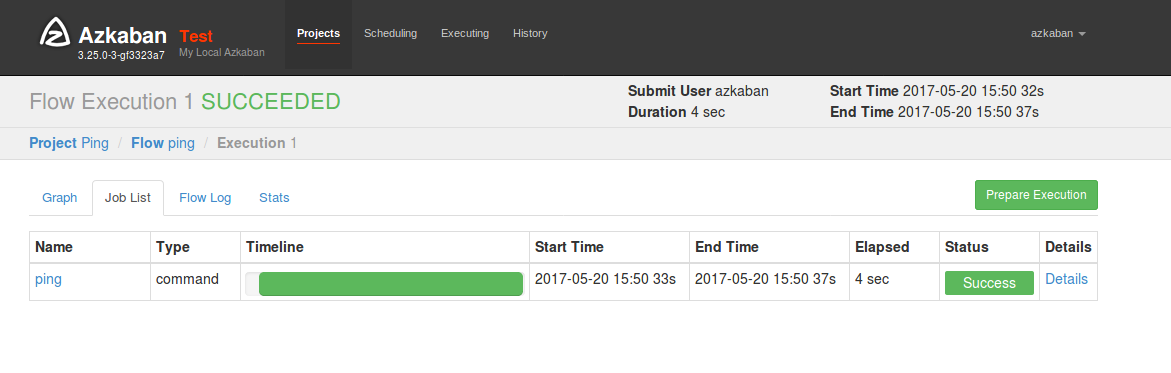
無事にpingが5回実行され成功しています。
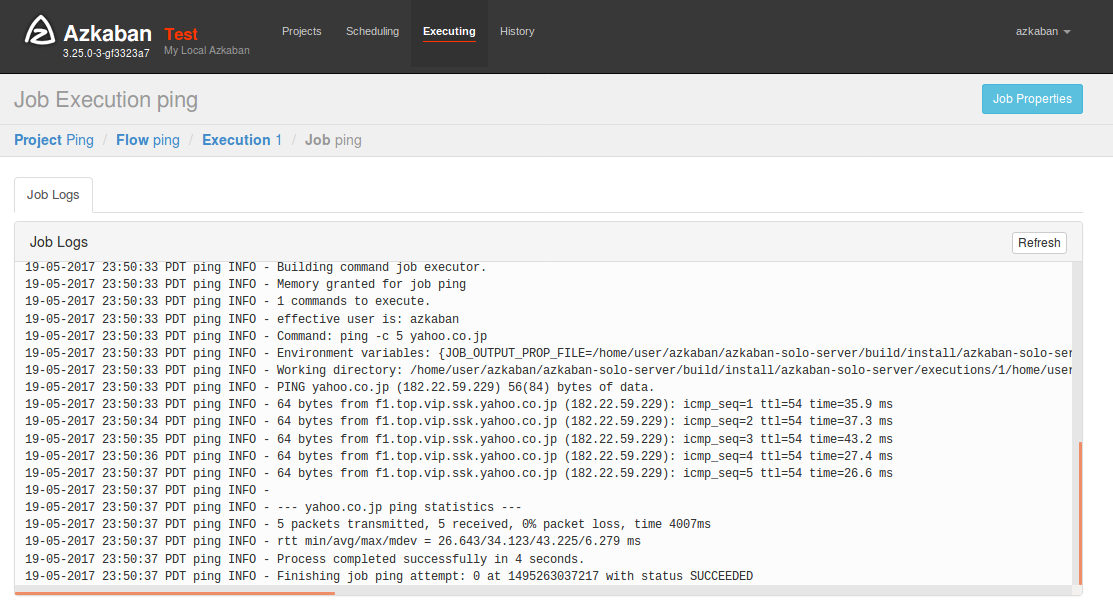
連続したフローの実行
次に連続したフローを作成して動作させてみます。Yahooへのpingを実行した後にGoogleへのpingを実行します。
$ vi ~/ping_yahoo.job type=command command=ping -c 5 yahoo.co.jp $ vi ~/ping_google.job type=command dependencies=ping_yahoo command=ping -c 5 google.com
2つのジョブを1つのzipファイルに固めます。
$ zip archive ~/ping_yahoo.job ~/ping_google.job -O ~/pings.zip
Project Pingを開いて、zipファイルをアップロードすると既存のフローが置き換わります。「Execute flow」ボタンを押します。
フロービューが表示されping_yahooの後にping_googleが実行されるのが分かります。ダイアログ右下のExecuteボタンを押します。
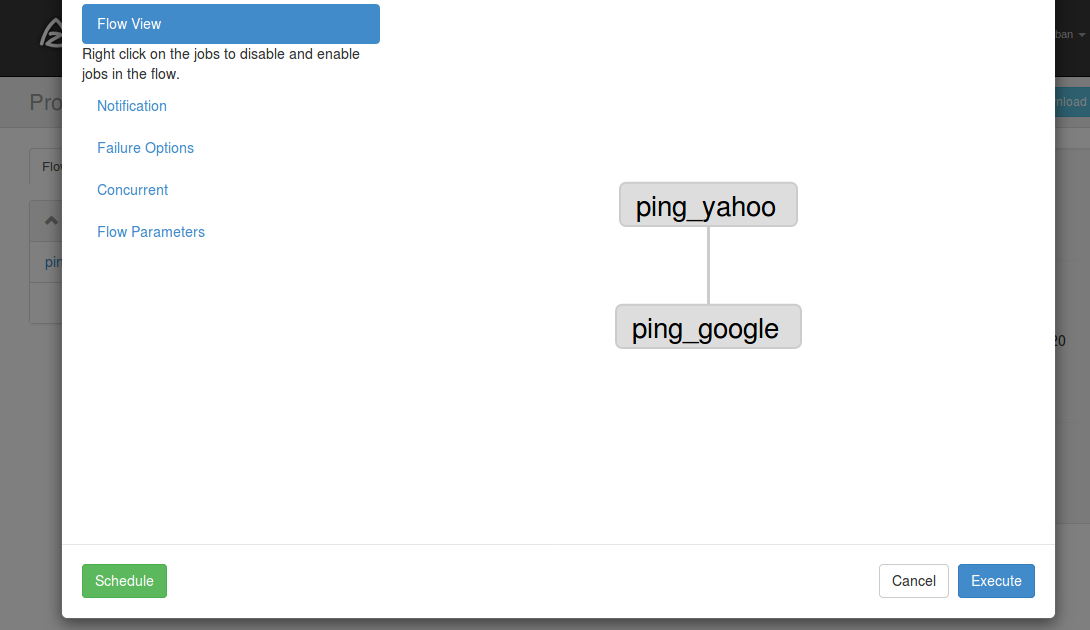
フローの実行結果を見ると連続して実行されたのが確認できます。
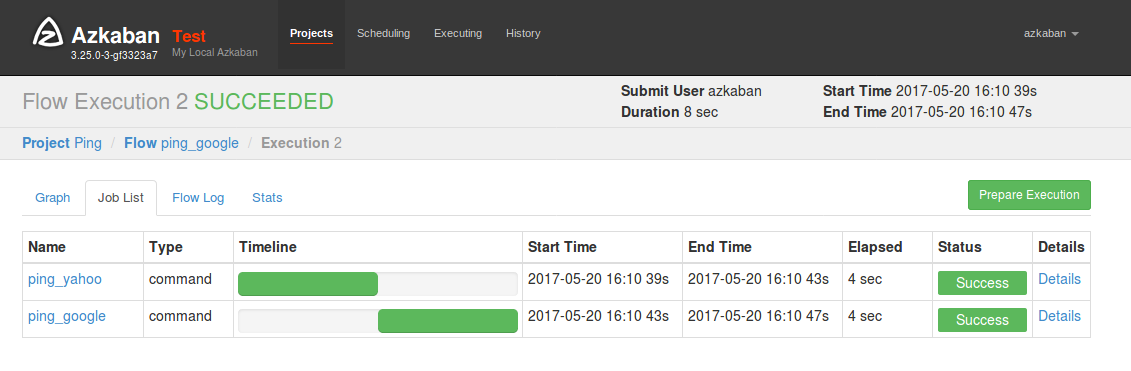
Yahooの後でgoogle.comへのpingが実行されています。
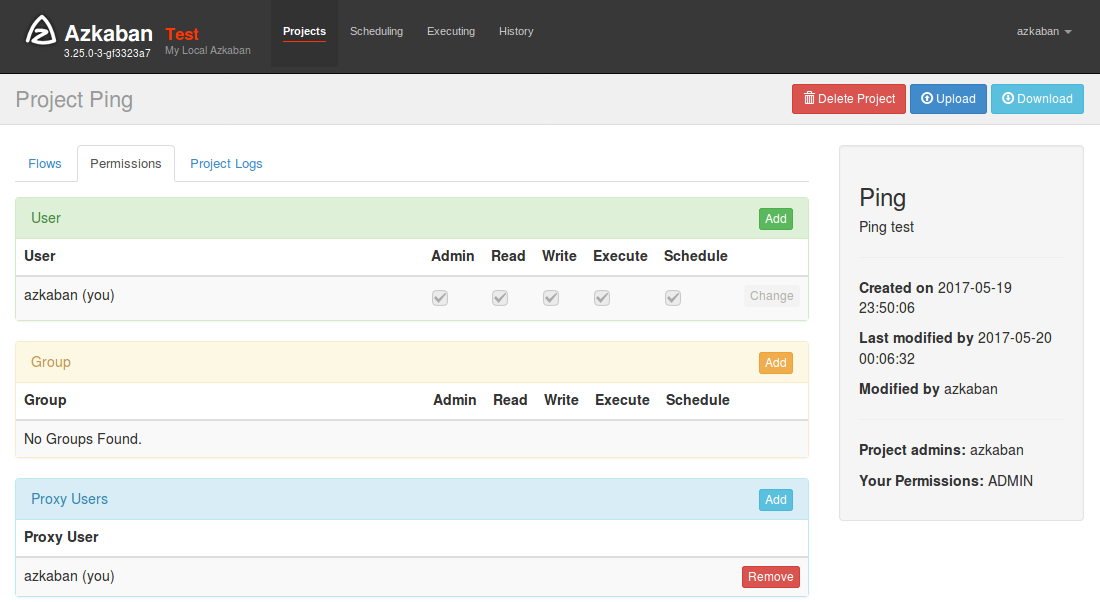
権限管理
Azkabanではプロジェクト単位のパーミッション管理が可能で、グループ単位やユーザー単位で実行権限を管理ができます。
カスタマーサポートチームは参照のみ、運用チームは実行が参照と実行可能と使い分けがし易くなっています。
まとめ
運用し易そうなワークフロー管理兼ジョブスケジューラーです。1台で完結するスタンドアローンな構成から、Hadoopクラスターを利用した大規模構成でも利用できます。
調べる中で、また試していく中でAzkaban特有と思えるコンセプトを見かけませんでした。ジョブスケジューラーとして王道的な設計ですので、既存ツールからの載せ替えや移植を行い易い印象です。
ミドルウェアを導入するリスクに時間が経過するとメンテナンスが行われなくなる点があります。Azkabanは2009年にリリースされてから、今2017年になっても開発とメンテナンスが継続して行われおり安心して利用出来そうです。
参考情報
https://azkaban.github.io/
http://azkaban.github.io/azkaban/docs/latest/
https://github.com/azkaban/azkaban
本ブログは、Git / Subversionのクラウド型ホスティングサービス「tracpath(トラックパス)」を提供している株式会社オープングルーヴが運営しています。
エンタープライズ向け Git / Subversion 導入や DevOps による開発の効率化を検討している法人様必見!
「tracpath(トラックパス)」は、企業内の情報システム部門や、ソフトウェア開発・アプリケーション開発チームに対して、開発の効率化を支援し、品質向上を実現します。
さらに、システム運用の効率化・自動化支援サービスも提供しています。
”つくる情熱を支えるサービス”を提供し、まるで専属のインフラエンジニアのように、あなたのチームを支えていきます。










No Comments